I was recently working in a PostgreSQL (9.6) environment and had one of those problems that comes around infrequently enough that it isn't a worn pattern in my brain. Contributing to this is the fact that I dwelt for a long time in SQL Server 2008 land which lacked a lot of functionality (lead/lag functions) that have been in the wild for quite a while.
Problem: Temporal transaction data that needed to be grouped into sequences. In this scenario, there is also an additional column by which the data is to be grouped.
The set-up code to demonstrate the approach:
drop table if exists seq_demo
;
create table seq_demo (
dt date
, grouping character varying
);
insert into seq_demo values ('2018-01-01', 'grp1');
insert into seq_demo values ('2018-01-02', 'grp1');
insert into seq_demo values ('2018-01-04', 'grp1');
insert into seq_demo values ('2018-01-05', 'grp1');
insert into seq_demo values ('2018-01-06', 'grp1');insert into seq_demo values ('2018-01-03', 'grp2');insert into seq_demo values ('2018-01-07', 'grp2');
insert into seq_demo values ('2018-01-08', 'grp2');
insert into seq_demo values ('2018-01-09', 'grp2');
insert into seq_demo values ('2018-01-10', 'grp2');
The above test data creates four sequences across the two groupings: { 'grp1', 'grp2' }
And we would like to transform this into the following output:
| 1 | grp1 | 2018-01-01 | 2018-01-02 |
| 2 | grp1 | 2018-01-04 | 2018-01-06 |
| 3 | grp2 | 2018-01-03 | 2018-01-03 |
| 4 | grp2 | 2018-01-07 | 2018-01-10 |
This is one approach that makes use of the lag function, following by a cumulative (windowed) sum to create the groups.
with lagged as (
select
dt
, grouping
, lag(dt) over (partition by grouping order by dt) as lagged_dt
-- the rn preserves row order for the next step, which is sometimes desired
, row_number() over (partition by grouping order by dt) as rn
from seq_demo
), grouped as (
select
dt
, grouping
, lagged_dt
, (dt - lagged_dt) as days_diff
, case when lagged_dt is null or (dt - lagged_dt) > 1 then 1 else 0 end as changed_dt
, sum(case when lagged_dt is null or (dt - lagged_dt) > 1 then 1 else 0 end)
over (partition by grouping order by rn rows between unbounded preceding and current row) as dt_group
-- note on postgresql "rows between unbounded preceding and current row" was not required
from lagged
)
grouping
, dt_group
, min(dt) as start_dt
, max(dt) as end_dt
from grouped
group by
grouping
, dt_group
order by
grouping
, dt_group
;
My results:
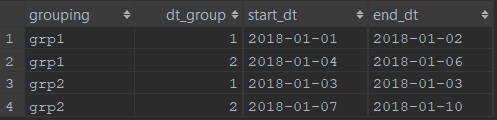
The specific use case this solved was to identify isolated transactions that had a group count of 1.
This pattern also works well to condense repeated dimensional data that appears in a transactional form.