A fair proportion of my work involves aspects of data quality i.e. munging data.
Routinely, there is a requirement to identify duplicate groups of records.
The following is a snippet that creates group ids from which further processing can be performed
1. Setup an example table
create table #tmp_cust (id int,group_field varchar(max),);insert into #tmp_cust values (1, 'attr1');insert into #tmp_cust values (2, 'attr1');insert into #tmp_cust values (3, 'attr1');insert into #tmp_cust values (4, 'attr2');insert into #tmp_cust values (5, 'attr2');insert into #tmp_cust values (6, 'attr3');
2. Use the lag function to determine when a the group field changes
with lagged as (
select
id
, group_field
, case when group_field <> lag(group_field) over (partition by 1 order by group_field, id) then 1 else 0 end as Group_Flag
from #tmp_cust tc
)
3. Use a cumulative sum; achieved by rows unbounded preceding in the window function.
select
id
, group_field
, sum(Group_Flag) over (order by group_field, id rows unbounded preceding ) as Group_Flag
from lagged
Results:
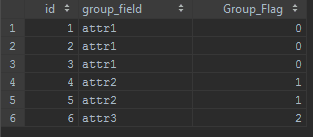
With the groups identified we can then move onto removing/remediation of duplicates!
(Tested using SQL Server 2016)